
The prequel to the ‘A Quiet Place’ saga got me thinking.
spoiler alert!
There is a scene in which many humans march towards a safety point. Each individual human would have been relatively quiet, but because there are a lot of them (potentially hundreds), they end up being, as a whole, loud enough to alert the monsters so they get all killed.
This would suggest that many sources of noise which are near to each other and generate more or less the same amount of noise end up adding up so that the end result in dB is more or less the sum of the individual dB levels.
But then again, it’s fiction.
Back to reality, I work in a room full of different servers which have also very different levels of noise. I have noticed that from my standpoint, the noise of the quietest server seems to disappear whenever the loudest is running, so it kind of does blow my mind how our perception of noise works…
Idk about the additive effects, but:
Fan noise especially is very “white” in the sense that it contains a lot of frequencies from low to high. That makes it ideal for overpowering (and subjectively swallowing) other noises (like other fans, speech, etc).
Fan noise
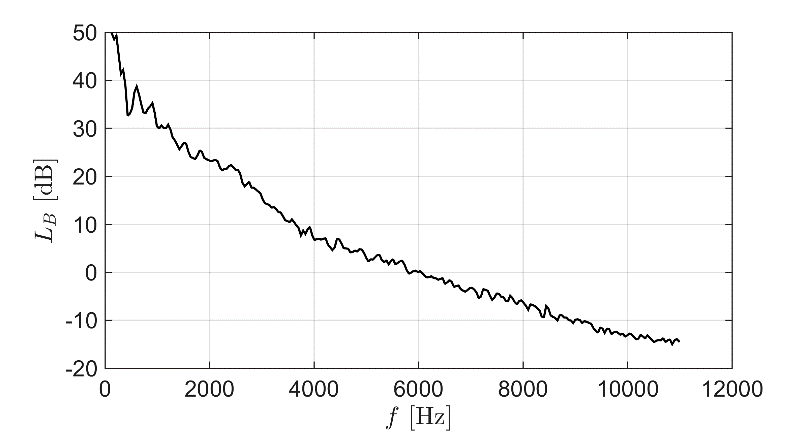
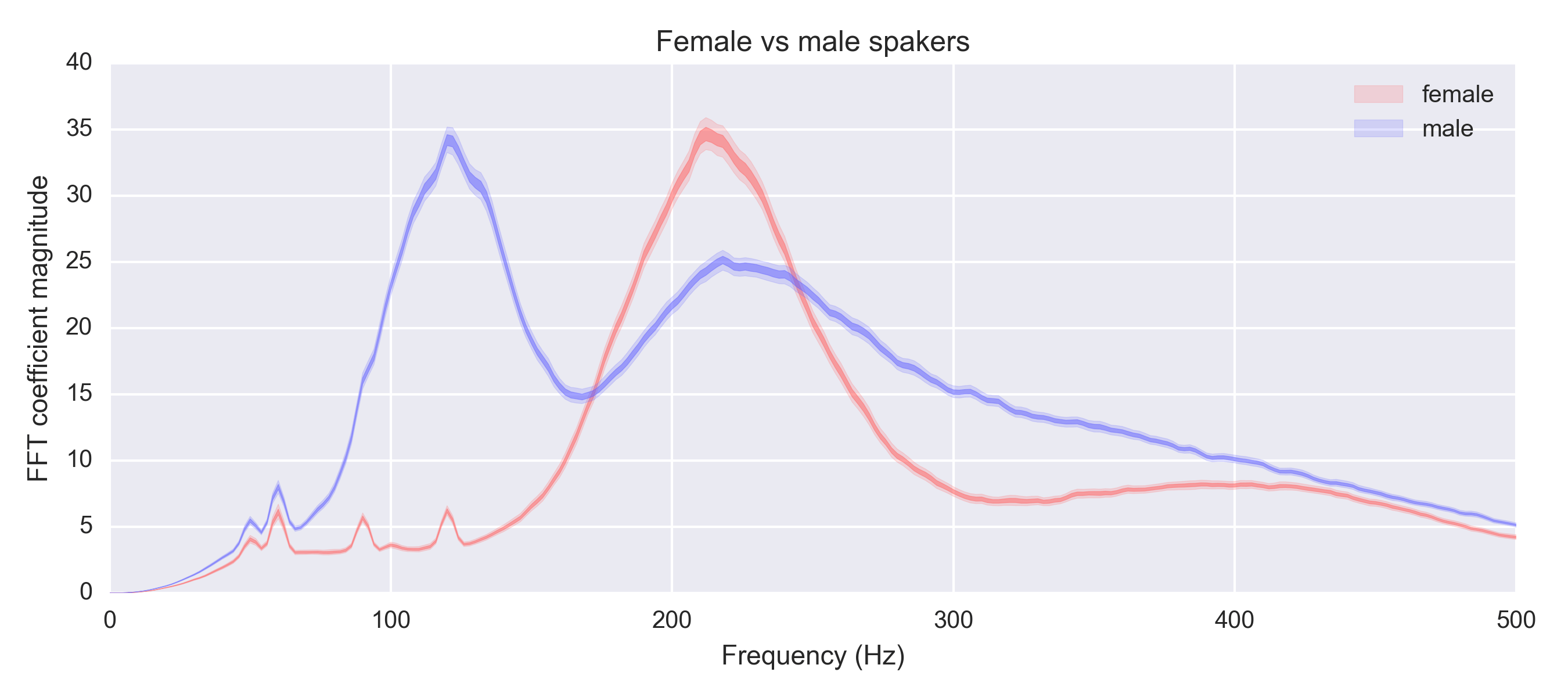
Speech for comparison happens in a frequency band where fans are very strong
Running water is similar. When you try to listen to a conversation or a video with speech while washing your hands, you will have a hard time understanding anything. With other noises that are in different frequency bands or only use very small range of frequencies it wont have that effect even if the noise is much louder than the running water was.
Noise cancelling in the sense that one noise actually makes another noise disappear, doesnt really happen under non lab conditions. Its more of a drowning out effect where your ear/brain cant differentiate the two noises anymore.
Selective hearing can do a lot of work by processing the signals from your ear in your brain, but that isnt all powerful.
Sorry for the very tangent.
That speech frequency graph is a good visual of why for trans voice training, resonance is more important than pitch. The pitch is nearly the same, the difference is in which overtones are projected.
Where did you find it? I would like to read more about the methodology.
I just looked for “human speech frequency spectrum” images so i had to tineye it to find it again but this seems to be the source
https://erikbern.com/2017/02/01/language-pitch.html
I cant vouch for its quality, but it seems pretty in depth from a quick scroll.